(Part #9) ML does work, but it’s not magic
Previous topic: (Part #8) Product matching via ML: Testing on various industries/languages
Next topic: (Part #10) Product matching via ML: The results
Since we said that we cannot afford to have wrong matches in Price2Spy, we were particularly careful when testing ‘false positives’ – these were matches where ML scored a potential match with a very high score (97%), while in fact, it was not a match. Why were such cases happening in the first place?
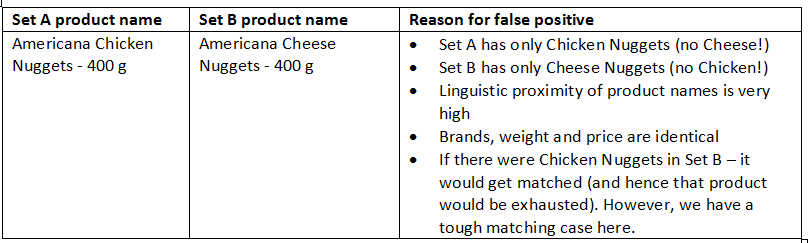
We spent quite some time trying to find a solution to the above problem. The proper solution would be to introduce Chicken and Cheese as entities, in order to help ML process learn that such to words cannot be considered a match, although the remainder of the product attributes is 100% identical. However, where would such an approach take us – how many entities would we end up with, and how many entities are we going to need? The idea was theoretically great, but not applicable in practice.
We have encountered a few more problems, which we categorized in the following way:
- Problems that we can solve with improvements in the ML process
- Missing data – we have noticed that in many cases product data taken from certain websites was incomplete. For example, the Brand field was empty. This particular problem we were able to fix with an addition to our ML pre-processor (by filling in missing Brand names)
- Spelling mistakes – product data is not free of such problems. Fortunately, ML blocking mechanism is configurable, so we were able to eliminate such problems by loosening up parameter values
- Brands with synonyms – for example, General Electric is a synonym for GE
- Problems that we cannot solve (and thus we will not attempt to solve them)
- Wrong brands – again, caused by data impurity on competitor websites. Since Brand is an important feature in the ML model, having a wrong brand almost certainly means that match will not be established
- The wrong price – believe it or not, we have also encountered situations where the price was wrong (423 instead of 42.3 EUR). Again, price is another important feature in the ML model, having a price which is very off will certainly mean that the match will not be established
ML working together with humans
In a previous couple of minutes we have reached 2 important conclusions:
- There are certain gaps in data that we won’t be able to fix in an automated way
- ML accuracy is above, 95%, we can improve it further, but it will never ever reach the 100% goal (and we cannot afford to have wrong matches in Price2Spy product matching)
Conclusion: we cannot eliminate the human factor in product matching!
So, instead of aiming for full automation, we should aim for something else: ML process which will reduce the amount of human product matching effort.
Let’s formalize the idea:
- There will be a very small number of matches established by ML (the ones with highest scores) which won’t need to be approved by humans. These products will be considered as exhausted for other potential matches.
- In all other cases, ML will return N best matching candidates (below we will explain how we have reached optimal N). These candidates would need to be checked by humans and confirmed as good matches (we call this promote/reject process)
The next question is – if we are using the human workforce to confirm if matches are OK – why do we go for the ML process in the first place? The question is perfectly valid, and it brought us to the last stage of our project – the Benefit Calculator.
Benefit Calculator
Let’s suppose that we need to match A products from the client’s site to 1 competitor’s site. This means that our human colleagues in charge of manual matching will have to perform A matching combinations.
However, what our human colleagues need to do in case of ML matching process is different
- Instead of looking for a match, they will need to promote/reject matching candidates. This requires less effort – and we’ll call this effort M. We have calculated that typical M is between 0.3 and 0.5 as opposed to 1.0 (in case of pure manual matching)
- When checking N matching candidates:
- If we promote the very 1st one – there will be no need to check other candidates for the same product (they should be automatically rejected). So, we have spent the human effort of M.
- If we promote the 2nd one – there will be no need to check other candidates for the same product (they should be automatically rejected). So, we have spent a human effort of 2xM.
- etc etc
- If we reject all N matching candidates, and none of them if promoted, we will need to do manual product matching once again – meaning that the total effort is 1+NxM (which is of course not good – but such cases will be inevitable)
- So, in order for our ML model to be cost-effective, we need to have moderate value for N (we have established that in most cases N = 3 is optimal)
- The power of the ML matching model goes higher as M goes lower (which depends on the industry).
- ML matching process does come with an overhead – we need to account for:
- Data collection (someone needs to prepare B data sets)
- QA of data from Set B
- Executing the ML process
So, what does the Benefit Calculator do – it checks the amount of human work needed to check the matching candidates provided by the ML matching process, as opposed to the effort needed for pure human matching.
What results did we get by the Benefit Calculator? Leaving it to the next chapter…
More useful links:
Previous topic: (Part #8) Product matching via ML: Testing on various industries/languages
Next topic: (Part #10) Product matching via ML: The results


